Note: This page is WIP.
Data gathered
Analysis of data on transfer 2
https://docs.google.com/spreadsheets/d/1W2UgFUmEbegR7VMsnUi3rrQDAeBYyenILFHH_0YpRdQ/edit?usp=sharing
Analysis of data on transfer 3
https://docs.google.com/spreadsheets/d/1Ks75ExHoLx6cxam9DRbztREzG-FpQ6f7RkS6otcYjpI/edit?usp=sharing
Analysis of data on transfer 4
https://docs.google.com/spreadsheets/d/1BEQ4IBtftvssiLcdCh7npVuuUGW1DlL_y6031D2lMOw/edit?usp=sharing
Analysis
All the info was gathered as seen by rnode.
The code used is available here:
https://github.com/dzajkowski/rchain/tree/wip-bloat-analysis
GNAT
Based on "Analysis of data on transfer 2"
A GNAT holds:
- channels - the name used in to send or receive
- data - produce, send
- continuations - consume, receive
size of leaf + node + skip := (1738 + 90014 + 19134) / 2 /* - replay */ => 55443
Data and continuations size
Data cost
Transfer from Bob to Alice
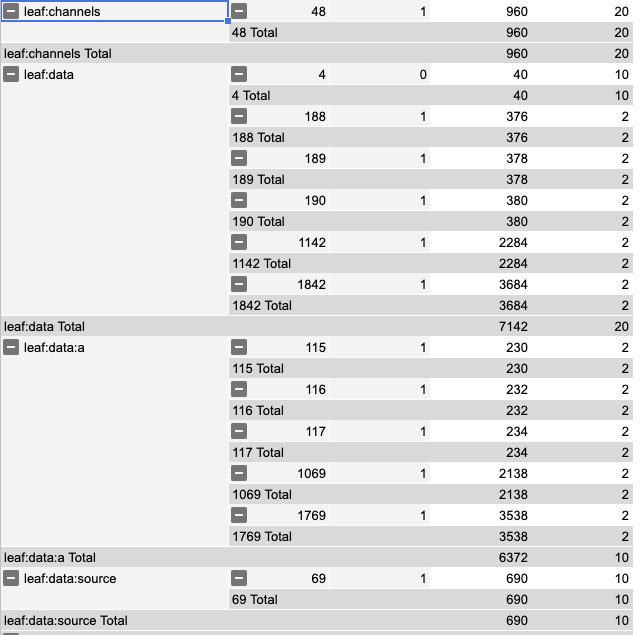
A Datum holds:
- source - checksums for event tracking
- a - produce data
size of data := 7142 / 2 /* (- replay) */ => 3571 (100%) size of a := 6372 / 2 => 3181 (89%) size of source := 690 / 2 => 345 (10%)
Deeper dive into the AST
based on "analysis of data on transfer 3"
size of A in Data := 3185 size of pars := 2689 (84%) size of top level random state := 494 (16%)
Continuations cost
Transfer from Bob to Alice
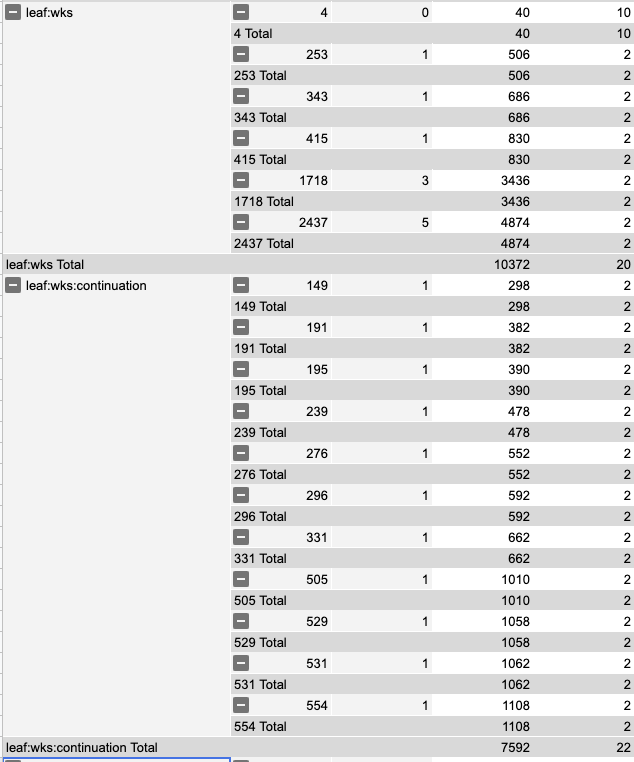
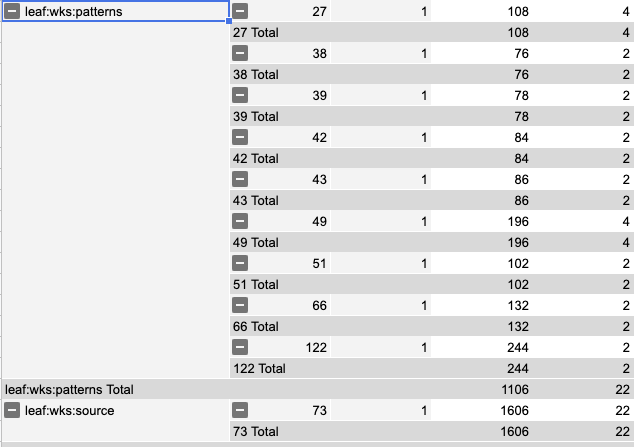
A WaitingContinuation holds:
- continuation - consume data
- source - checksums for event tracking
- patterns - used for spatial matching
Size of continuations being shuffled during a transfer:
size of wks := 10372 / 2 /*(- replay)*/ => 5186 (100%) size of continuations in wks := 7692 / 2 => 3946 (76%) size of source := 1606 / 2 => 803 (15%) size of patterns := 1106 / 2 => 503 (10%)
Deeper dive into the AST
based on "analysis of data on transfer 3"
size of wks := 5 186 size of continuation par := 2 536 (50%) size of continuation top level random := 1 088 (20%) size of patterns := 553 (10%) size of source := 804 (16%)
Trie size
Leaf cost
Leafs are cheap themselves, the data usage comes from the size of data stored.
Skip cost

size of skip := 1738 / 2 /* -replay */ => 869
Node cost
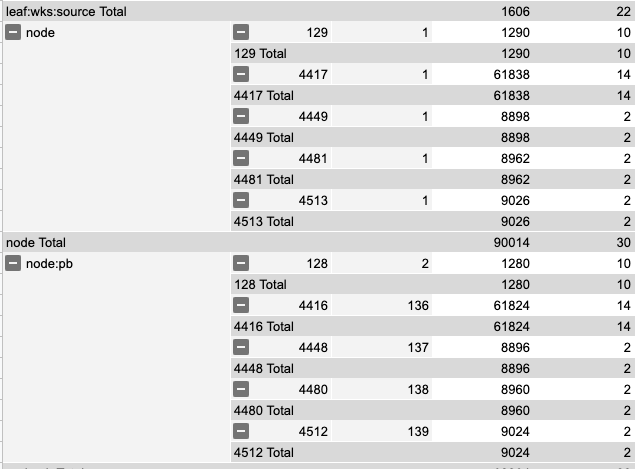
size of node:pointerblocks := 89984 / 2 /* (- replay) */ => 44992
Size on disk
LMDB
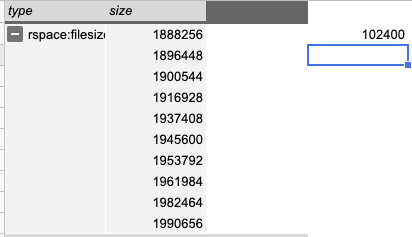
observed size on disk := 102400 / 2 /* (-replay) */ => 51200
Observations
| % of total | |
|---|---|
| leaf | 17% |
| leaf:data | 6% |
leaf:continuation | 9% |
| node | 81% |
| skip | 2% |
Takeaways/next steps
- Work through checkpoint creation (1 step instead of 13 steps) which would reduce the amount of stored tries (less data)
RCHAIN-3415
-
Getting issue details...
STATUS
- estimated gain:
- store of top level pointerblock (4416 + 4512 + 128) instead of 44992 (80%)
- note: this calculation is very imprecise as the change will happen (is possible) in next rspace
- Address EmptyPointer stored in Node pointer block.
RCHAIN-3226
-
Getting issue details...
STATUS
- encode pointer type in 2 bits, not in 8 bits
- explore gain from storing sparse vectors
- estimated gain:
- Continue analysis of rholang AST
- we can address the source size (which is constant but it constitutes a 10% or 15% of the data stored)
- there is no way of addressing the random state