Note: This page is WIP.
Data gathered
Analysis of data on transfer 2
https://docs.google.com/spreadsheets/d/1W2UgFUmEbegR7VMsnUi3rrQDAeBYyenILFHH_0YpRdQ/edit?usp=sharing
Analysis of data on transfer 3
https://docs.google.com/spreadsheets/d/1Ks75ExHoLx6cxam9DRbztREzG-FpQ6f7RkS6otcYjpI/edit?usp=sharing
Analysis of data on transfer 4
https://docs.google.com/spreadsheets/d/1BEQ4IBtftvssiLcdCh7npVuuUGW1DlL_y6031D2lMOw/edit?usp=sharing
Analysis
All the info was gathered as seen by rnode.
The code used is available here:
https://github.com/dzajkowski/rchain/tree/wip-bloat-analysis
All the gathered data is doubled since the deploying node has to run replay on the same data.
GNAT
Based on "Analysis of data on transfer 2"
A GNAT is held by Leaf (vide: trie analysis, lower)
A GNAT holds:
- channels - the name used in to send or receive
- data - produce, send
- continuations - consume, receive
size of leaf + node + skip := (1738 + 90014 + 19134) / 2 /* - replay */ => 55443
Data and continuations size
Data cost
Transfer from Bob to Alice
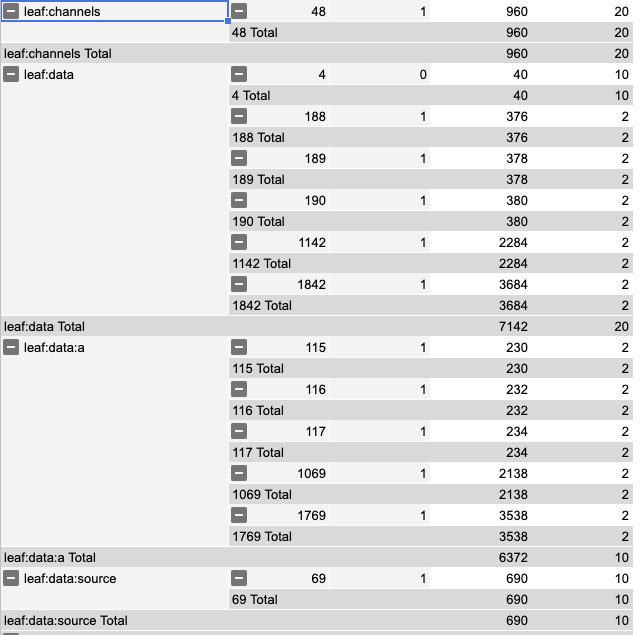
A Datum holds:
- source - checksums for event tracking
- a - produce data
size of data := 7142 / 2 /* (- replay) */ => 3571 (100%) size of a := 6372 / 2 => 3181 (89%) size of source := 690 / 2 => 345 (10%)
Deeper dive into the AST
based on "analysis of data on transfer 3"
size of A in Data := 3185 size of pars := 2689 (84%) size of top level random state := 494 (16%)
Continuations cost
Transfer from Bob to Alice
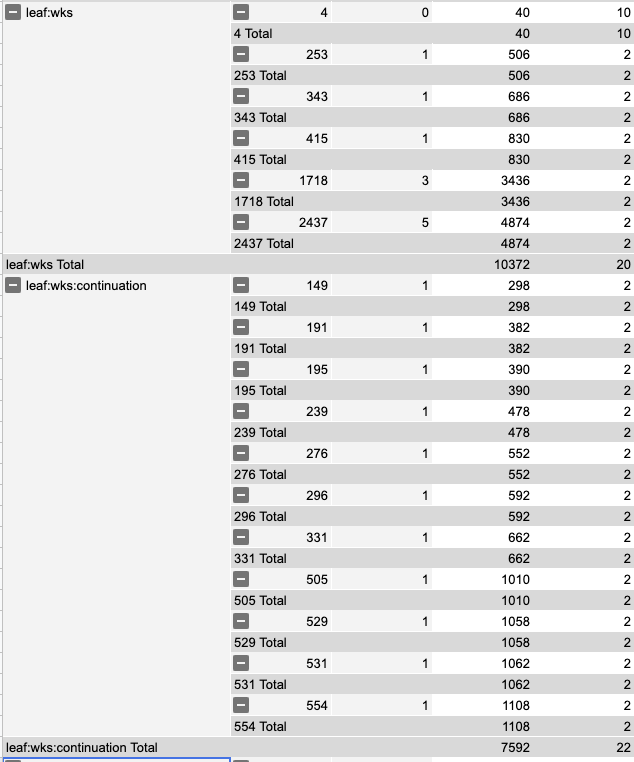
A WaitingContinuation holds:
- continuation - consume data
- source - checksums for event tracking
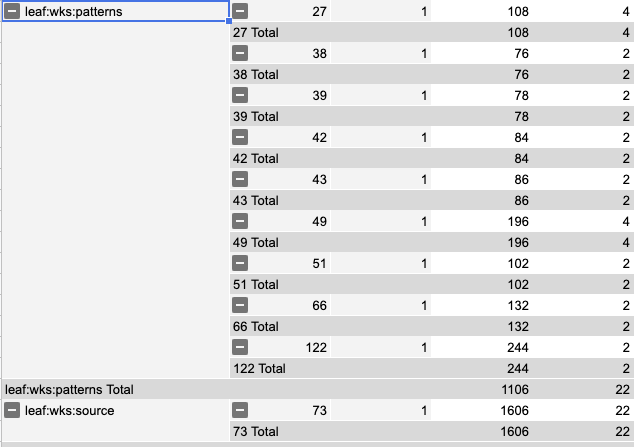
- patterns - used for spatial matching
Size of continuations being shuffled during a transfer:
size of wks := 10372 / 2 /*(- replay)*/ => 5186 (100%) size of continuations in wks := 7692 / 2 => 3946 (76%) size of source := 1606 / 2 => 803 (15%) size of patterns := 1106 / 2 => 503 (10%)
Deeper dive into the AST
based on "analysis of data on transfer 3"
size of wks := 5 186 size of continuation par := 2 536 (50%) size of continuation top level random := 1 088 (20%) size of patterns := 553 (10%) size of source := 804 (16%)
Trie size
Leaf cost
Leafs are cheap themselves, the data usage comes from the size of data stored.
Skip cost

size of skip := 1738 / 2 /* -replay */ => 869
Node cost
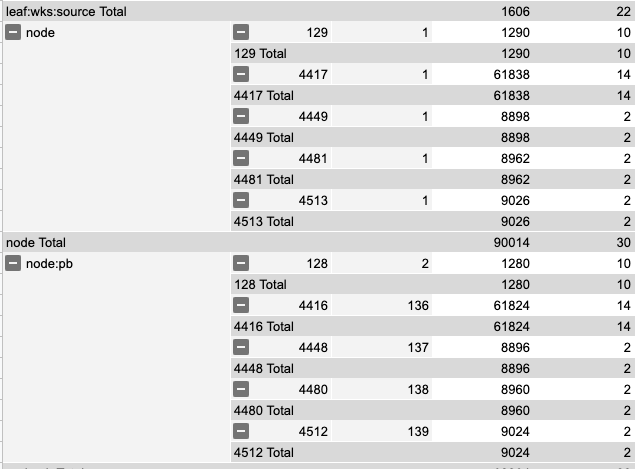
size of node:pointerblocks := 89984 / 2 /* (- replay) */ => 44992
Size on disk
LMDB
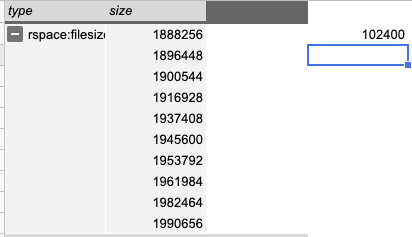
observed size on disk := 102400 / 2 /* (-replay) */ => 51200
Observations
| % of total | |
|---|---|
| leaf | 17% |
| leaf:data | 6% |
leaf:continuation | 9% |
| node | 81% |
| skip | 2% |
Thoughts
Thought experiment 1
Let's assume that:
- the system is operating at 1500 COMM/s
- it takes 50 COMM events to transfer X from A to B
- the random state is the only thing we track in history
one random state takes up 100 bytes
we are able to process 30 rev txns/s (1500 / 50)
This results in 10MB of random state per hour, 1.7GB in a week.
Thought experiment 2
Let's assume that:
- there are 20000 active rev vaults being used
- each rev vault lives on a dedicated channel
- the keys are evenly distributed
each key weighs 32 bytes
each node can hold up to 256 keys
To be able to track 20k unique channels it takes a trie that:
- has a filled 0 level node (256 * 32 bytes)
- the 1 level is able to index 65 536 keys
- we use 20k of those keys
- the rest of the structure needs a leaf and a skip per key - 64 bytes each
The structure that tracks 20k active accounts weighs:
- level 0: 8 192
- level 1: 640 000
- skip + leaf: 1 280 000
So to track a block that has 20k rev transactions we need a total of 1 928 192 bytes on disk.
Thought experiment 3 (1 + 2)
Assumptions 1 & 2 hold.
we can have 20k rev transactions in 667 seconds, 12 hours.
Let's assume that we only create a block when we have 20k rev txns accumulated.
The lower limit of the cost on disk is: 12*10MB + 2MB = 122MB per block.
The cost of the above will go up with the frequency of block creation (only whole nodes can be shared).
Takeaways/next steps
- Work through checkpoint creation (1 step instead of 13 steps) which would reduce the amount of stored tries (less data)
RCHAIN-3415
-
Getting issue details...
STATUS
- estimated gain:
- store of top level pointerblock (4416 + 4512 + 128) instead of 44992 (80%)
- note: this calculation is very imprecise as the change will happen (is possible) in next rspace
- Address EmptyPointer stored in Node pointer block.
RCHAIN-3226
-
Getting issue details...
STATUS
- encode pointer type in 2 bits, not in 8 bits
- explore gain from storing sparse vectors https://rchain.atlassian.net/projects/RCHAIN/issues/RCHAIN-3227
- estimated gain:
- Continue analysis of rholang AST
- we can address the source size (which is constant but it constitutes a 10% or 15% of the data stored)
- there is no way of addressing the random state
Trie Merging in RSpace Next
Transfer from A → B, existing wallets.
The experiment was performed on a clean rnode instance with genesis and
- vault_demo/0.create_genesis_vault.rho
- vault_demo/2.check_balance.rho
- vault_demo/3.transfer_funds.rho
run to prime the data.
What is gathered in the sheet is the result of a second vault_demo/3.transfer_funds.rho run.
https://docs.google.com/spreadsheets/d/1v5MJhKyzu1WgzAQo51rHt0TNXeBOffbQ9bUgldxHeUw/edit?usp=sharing
The trie structure weighs 7020 bytes.
It's easy to observe that there is one central PointerBlock which weighs 4929 bytes.
This cost seems to be very close to the lower bound for any change to the trie. This would dictate that any actions on a block should focus on performing as much actions in memory and committing (checkpointing) as seldom as possible.
This also points to work done in RCHAIN-3453 - Getting issue details... STATUS
On a side note: RSpace Next does not hold a separate data bag for replay, so the data is not duplicated.
Thought
One could make a case that the highest level PointerBlocks (let's say 3 levels) will change constantly and will be heavily populated (256 * 32 bytes).
Maybe it would make sense to differentiate them from the pointer blocks that will live lower in the trie and invest in some sort of structure sharing.
But at the time of writing no such structure (that would save space) comes to mind.
At the same time if the deployments passed to trie creation are diverse enough this will become a mute point as the structure will be shared in a limited fashion.
This needs further investigation to merit any further code changes.