Storage Specification & Design - Deprecated
This document is deprecated. Please reference: (deprecated) RSpace 0.1 Specification
1. Introduction
The purpose of this document is to provide a specification of the RChain storage layer that is sufficient to allow an engineer to write a package that satisfies the available requirements, to the extent that the requirements are known. The areas where the requirements are not available are noted.
The intended audience of this document is engineers who understand the basics of:
- blockchain
- key-value store database
- Prolog logic programming language
The important RChain document for the storage layer is the “RChain Platform Architecture,” found at http://rchain-architecture.readthedocs.io/en/latest/index.html. The other sources that are referenced in this document are listed in the Bibliography.
2. RChain Architecture Overview
RChain is a “decentralized, economic, censorship-resistant, public compute infrastructure and blockchain. It will host and execute programs popularly referred to as ‘smart contracts’. It will be trustworthy, scalable, concurrent, with proof-of-stake consensus and content delivery.” (Arch Doc)
The RChain system is made of up of a network of nodes, where each node runs the RChain platform. In each node, the RhoVM Execution Environment provides the context for contract execution. Each node stores subsets of the entire blockchain comprised of the blocks that are relevant to the contracts that the node runs.
The following diagram displays the components of a node that interact with the storage layer. The contacts are written in the Rholang programming language and interact with the storage layer through the RhoVM. RhoVM determines which blocks of the blockchain are held in the storage layer. The communications layer handles all the network interactions with other nodes, including node discovery, inter-node trust, and transport.
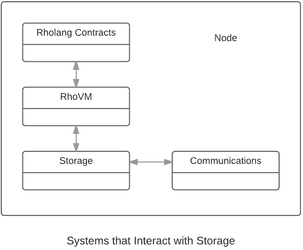
Some nodes are validators, which
- apply a consensus algorithm to authenticate and extend the blockchain with new blocks, and
- disseminates the new blocks to other nodes.
Since the validator functions are executed by the RhoVM, it is considered a part of the RhoVM for the purposes of the storage layer.
2.1 Execution Layer
RhoVM operates against a key-value data store. A state change of RhoVM is realized by an operation that modifies which key maps to what value. (p. 20)
2.1.2 RhoVM Execution Environment
The RhoVM Execution Environment is a Scala implementation of the Rosette VM. Rosette is a reflective, object-oriented language that achieves concurrency via actor semantics. (Arch Doc)
2.1.3 Rholang and Contracts
2.1.3.1 Continuations
Token contract uses continuations.
A continuation is the rholang program and its state.
Kent says that there is no way to detect that a continuation won't be executed again. This is unfortunate because it would shrink the database to prune continuations that aren't needed.
2.1.3.2 Destructure of Keys, Tuplespace, Namespaces
Example of destructured assignment to key
Tuplespace is "a logical repository above the physical and communications layers of the Internet. The repository is essentially organized as a distributed key-value database in which the key-value pairs are used as communication and coordination mechanisms between computations." (p.6 Mobile process)
Keys in tuplespace map to storage.
2.2 Storage Layer
A variety of data is supported, including public unencrypted json, encrypted BLOBs, or a mix. This data can also be simple pointers or content-hashes referencing off-platform data stored in private, public, or consortium locations and formats. (page 26, Arch Doc)
SpecialK is the DSL for data access, while KVDB is a distributed-memory data structure behind the DSL. SpecialK defines distributed data-access patterns in a consistent way, using the modifiers “Persistent” and “Ephemeral.” TODO TBD (page 26, Arch Doc)
The query semantics vary depending on which level in the architecture is involved. At the SpecialK level, keys are prolog expressions, which are later queried via datalog expressions. Higher up in the architecture, prolog expressions of labels are used for storage, and datalog expressions of labels are used for query. (page 27, Arch Doc)
“KVDB - Data & Continuation Access, Cache
Data will be accessed using the SpecialK semantics, while physically being stored in a decentralized, Key-Value Database known as “KVDB”. A view of how two nodes collaborate to respond to a get request is shown below:
- The node first queries its in-memory cache for the requested data. Then if it is not found it,
- queries its local store, and, if it is not found, stores a delimited continuation at that location, and
- queries the network. If and when the network returns the appropriate data, the delimited continuation is brought back in scope with the retrieved data as its parameter.”
(page 27, Arch Doc)
2.2.1 Requirements of the Execution Layer
2.2.1.1 Prolog and Unification
In the full implementation of RChain, keys will be Prolog terms. For Mercury, the keys will be flat and of the form rholang-X, where X is a hexadecimal number. TODO I didn’t ask for the length of the ID.
Value of a key is data or continuation
A key will either be associated with a set of data or a set of continuations because data and continuations are noever on the same channel.
2.2.1.2 Requirements of the RhoVM
Does VM have registers that need to be stored? No.
How large can VM queue grow? Bounded only by memory? TDB
Rholang needs to associate multiple continuations with a single key.
The Rholang primitive types are Booleans, Integers, Double, and Strings as described in rchain/rholang/src/main/bnfc/rholang.cf.
2.2.1.3 Blocks
Blocks are not just a list of transactions. They are little programs, which extend out to the affected transactions list. The programs that have consensus around them, they have the most 'weight' behind the proposal - this is stake weight. The 'fork choice' rule says that when you take a fork, it's the one that has the most stake behind it.
In the python code in https://github.com/ethereum/cbc-casper the longest list of justifications associated with a block never exceeds the number of validators. The number of validators is set in a configuration file, config.ini. In the actual implementation of the blockchain, it is unlikely that there will be a limit on the number of validators. Therefore, the list of justifications associated with a block is unbounded at this time.
How to find the genesis block? TBD
Does the blockchain require an index? TBD
2.2.1.3.1 A Block can have multiple parents
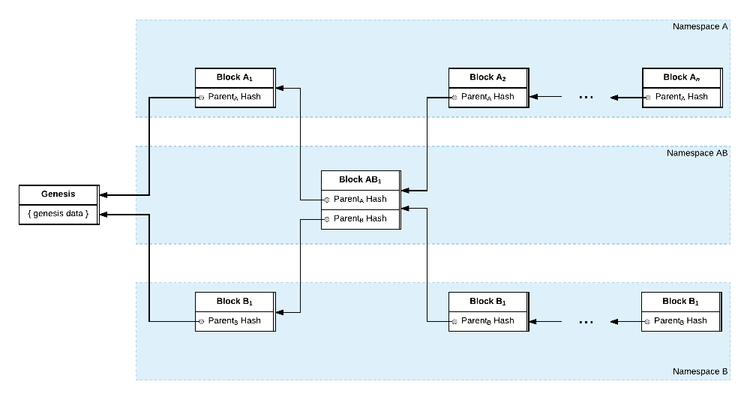 2.2.1.3.2 Open questions
2.2.1.3.2 Open questions
https://rchain.atlassian.net/wiki/spaces/CORE/pages/10223617/Open+questions says that the following are not specified:
- What hashes are there, and what do they look like?
- What data is common to all blocks?
- What is the size of a block? Can block sizes vary?
- Are there "light blocks" constructible for "light clients"?
Encrypted blobs (page 26 of RChain Arch)
2.2.1.3.3 To Be Done
Logging
Monitoring
2.2.2 Requirements of the Communications Layer
Although the requirements that the communications layer has of the storage layer are not confirmed yet, the following requirements appear likely.
Each key will be associated with a single value and the value will be smaller than 512 bytes.
Data about the identity of the node in the RChain network.
Bootstrap address, which is part of the code itself and allows the node to find a pre-defined server
The communications layer will need to store data about the identity of the node in the RChain network. This data is being called an “rnode” and it “allows a node to come up with a stable name.”
It is plausible that the communications layer will use a scheme like Ethereum’s enode. See https://github.com/ethereum/wiki/wiki/enode-url-format. An example of an enode is:
An enode has the following parts, all of which are likely to be stored in the store.
- Protocol (in the enode example, this is “enode”)• ID (in the enode example, this is “6f8a80d14311c39f35f516fa664deaaaa13e85b2f7493f37f6144d86991ec012937307647bd3b9a82abe2974e1407241d54947bbb39763a4cac9f77166ad92a0”)
- IP address (in the enode example, this is “10.3.58.6”)
- TCP port (in the enode example, this is “30303”)
- UDP port (in the enode example, this is “30301”)
The communications layer is likely to need to store a private key. It is likely that the private key will be the largest value that the communications layer will store. The largest private key in common use is 4,096 bits or 512 bytes, which is not a problem to store.
It is likely that the node code will contain a “bootstrap address,” which presumably is an IP address for a server that provides a directory of nodes and validators. This bootstrap address may be stored in the store.
There may be a need to store information about other nodes in the network, including:
- ID
- IP address
- last know reputation
- black-list status
3. Design Considerations
3.1 Design Requirements
In general, the requirements of the storage layer are to:
- provide query unification and key-value storage for the RhoVM
- provide key-value storage for the communications layer
- store all the data necessary for the node to reconstruct its state after a crash, up to the most recently committed transaction
3.1.1. Unifier Requirements
Greg says we need arrays and structures for Mercury.
Value structure for storing a continuation in a serialized blob: \[ \[ x, y, z \], P \] where \[ x, y, z \] is an array pattern and P is a continuation
Data values, as opposed to continuation values, will be JSON blobs.
Keys from RhoVM are strings of the form of "rholang-" followed by a string representation of a numeric ID.
3.1.2 Node and Lmdbjava Requirements
While the hardware and software requirements to run a node are not defined yet, the hardware and software requirements of the storage layer are the same as those to run lmdbjava, the key-values store that underlies the storage layer.
Any OS that will run a Java Virtual Machine with a version of 8 or above
LmdbjavaJava 9 ready (JNR-FFI-based; Unsafe not required)
Support official JVMs running on typical 64-bit operating systemshttp://www.javadoc.io/doc/org.lmdbjava/lmdbjava/0.6.0
$ java -version
java version "1.8.0_131"Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
Memory or storage requirements unknown
Security requirements (or other such regulations) TBD
Standard DB
- Support ACID semantics
- Provide CRUD functionality
Values associated with a key
- Values can be large
- Values may be “blobs” with no structure apparent to the database. Continuations are treated as blobs
Roscala is implementing serialization so the storage layer doesn't need to.
3.1.3 Limitation on size of value
In a conversation on September 11, 2017, Mike asked Greg how big the blogs stored as values in the storage layer would be. He asked “Kilobytes? Megabytes? Gigabytes?” Greg answered, “Megabytes.” During the week of November 6, 2017, I spoke with Kent multiple times about if there was a maximum size on blobs or continuations. Kent had conferred with Greg and confirmed that there is no limit. I told Kent that the storage layer will have to set a limit on the size of a value.
On November 9, 2017, Mike asserted that it is the compiler’s responsibility to break a large continuation down to chunks of manageable size and to store the chunks in the storage layer.
Mike suggested that the maximum size of a value be 4 MB because the size of a Linux page is 4 KB and the size of the RhoVM address space is 4 GB and 4 MB is the midpoint between the two. It is likely that the size of the limitation will change, but this is the stake in the ground.
Unification
- Allow keys and values to have a structure like Prolog terms. Call this structure a “Prolog structure.”
- Support Prolog unification such that a key that has Prolog structure can be unified with keys or values in the database that have Prolog structure
3.2 Performance Requirements
To become a blockchain solution with industrial-scale utility, RChain must provide content delivery at the scale of Facebook and support transactions at the speed of Visa. website
“The most that Bitcoin can do on a good day is 10 transactions a second,” says Greg Heuss, an adviser helping RChain with its fundraising. “Visa can do 40,000 transactions in the same time.”
https://www.geekwire.com/2017/seattle-based-rchain-takes-bitcoin-ethereum-new-blockchain-tech/
4. System Architecture
The storage layer has two parts: a unifier and two Lmdbjava databases. The diagram below indicates that each lmdbjava interface wraps an lmdb instance, which is written in C. Further, each lmdb instance makes use of two database files: data.mdb and lock.mdb.

4.1 Unifier Subsystem
The implementation of unification in the storage layer is a restricted form of Prolog. Specifically, the storage layer includes Prolog facts but not rules.
In effect, unification in the storage layer begins with a query that is a Prolog term that contains a variable, and returns all the keys in storage that match that query.
Limitations here
Store unifiable keys in a structure that can be accessed quickly.
Specify unification algorithm
4.1.1 Use Cases
4.2 Lmdbjava Subsystem
4.2.1 Lmdb and lmdbjava
Lmdb is written in C and located at https://symas.com/lmdb/.
Lmdb provides ACID semantics and CRUD interface.
The performance of lmdbjava compared to lmdb is consistent with the performance of a generic Java program compared to the equivalent C program.
Lmdbjava is a Java wrapper for lmdb, which uses JNI and is located at https://github.com/lmdbjava/lmdbjava.
The performance of lmdbjava compared to lmdb is consistent with the performance of a Java program compared to equivalent the C program.
Lmdbjava does not enhance the functionality of lmdb, so in this paper, when I discuss the capabilities of lmdbjava I am also referring to the capabilities of lmdb.
The classes in lmdbjava are NOT thread safe. In addition, the LMBC C API requires you to respect specific thread rules (eg do not share transactions between threads). Lmdbjava does not shield you from these requirements, as doing so would impose locking overhead on use cases that may not require it or have already carefully implemented application threading (as most low latency applications do to optimize the memory hierarchy, core pinning etc).
Most methods in this package will throw a standard Java exception for failing preconditions (eg NullPointerException if a mandatory argument was missing) or a subclass of LmdbException for precondition or LMDB C failures. The majority of LMDB exceptions indicate an API usage or Env configuration issues, and as such are typically unrecoverable.
http://www.javadoc.io/doc/org.lmdbjava/lmdbjava/0.6.0
4.2.1 Lmdbjava does not support unsigned types
Lmdbjava is a Java package and Java does not have native unsigned types and as a consequence the storage layer does not offer unsigned types in its interface. There are Java packages that simulate unsigned types that we can add to address this deficiency.
4.2.2 Lmdb contrains the size of a key
The biggest key that lmdb accepts is 511 bytes.
4.2.3 Lmdb constrains the size of MDB_DUPSORT values
If lmdb is configured with MDB_DUPSORT then the size of a value associated with a key cannot exceed 511 bytes. See lmdb C code in mdb.c.
4.2.4 A key can be associated with multiple large keys
Greg, Mike, and I discussed the storage layer requirements in a call on September 11, 2017. Greg mentioned that each key may be associated with multiple blobs. Neither Mike nor I asked Greg if this requirement is a necessity. Further, on November 7, 2017, Kent confirmed that Rholang contracts require that a key be associated with multiple keys.
This requirement cannot be satisfied by the API exposed by lmdbjava. The problem is that when lmdbjava is configured to associate multiple values with a key, the size of those keys is constrained to 511 bytes. In this section, I explain this problem in more detail.
When you create an instance of lmdbjava in Scala, you specify that a key can be associated with multiple values by passing the MDB_DUPSORT parameter.
val db: Dbi[ByteBuffer] = env.openDbi(nameIn, MDB_CREATE, MDB_DUPSORT)
When MDB_DUPSORT is present, the size of each value is constrained to 511 bytes.
Since clients of the storage layer want to associate multiple large values with a key, we need to work around this limitation in lmdbjava.
The solution is to use two lmdbjava databases, one configured with MDB_DUPSORT and one that is not. The one that is not configured with MDB_DUPSORT can associate a key with a single large value. Call the MDB_DUPSORT database the keyDb and the non-MDB_DUPSORT database the valueKeyDb.
When a client of the storage layer adds a key and a value, we generate a small intermediary value that functions as a key to the larger value in the valueKeyDb. Call this intermediary value a “value-key.”
For example, suppose we have a key k with which we want to associate two large values named bigValue1 and bigValue2. When the client associates k with bigValue1, we generate a value-key vk1 and associate k with vk1 in the keyDb. In the valueKeyDb, we associate vk1 with bigValue1. Similarly, when the client associates k with bigValue2, we generate a value-key vk2 and associate k with vk2 in the keyDb and associate vk2 with bigValue2 in the valueKeyDb.
When the client wants to retrieve the values associated with k, we retrieve vk1 and vk2 from keyDb. We look up the values associated with vk1 and vk2 in valueKeyDb and return those to the client.
The main problem to be solved is how to generate unique value-keys. There are two simple approaches that are insufficient. The first approach is to simply use a timestamp for the value-key. This won’t work because most clocks are only accurate to milliseconds and many database insertions can happen in a millisecond. The second approach is to generate a long random as a value-key. This approach is insufficient because in my testing I found that in multiple tests when I generated 100,000 random variables there would be duplicate random values.
The solution is to combine both approaches in the generation of the value-key. Specifically, given a key, the value-key is generated with these steps:
- Create a string representation of the key.
- Create a string of the form _XXXXXXXXXXX_XXXXXXXX, where the leftmost bunch of 11 Xs are hexadecimal digits representing the time in milliseconds and the rightmost bunch of 8 Xs are hexadecimal digits representing a random number.
- Append the string from step 2 to the string from step 1.
Thus the generated value-key has the form <key as string>_XXXXXXXXXXX_XXXXXXXX.
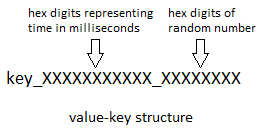
Admittedly, my solution does not guarantee uniqueness, but I believe it is as close as we can get and minimizes the chance of collision.
One consequence of using this approach is that the maximum size of a key is 490 bytes because the last 21 bytes are devoted to the _XXXXXXXXXXX_XXXXXXXX string appended to the end of the value-key.
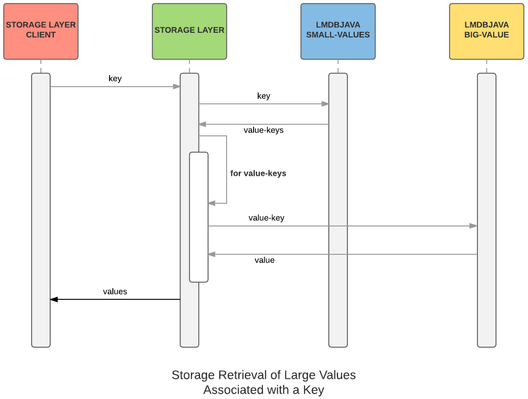
This diagram show the submission of a query that returns multiple large values associated with that key.
“LMDBJAVA SMALL-VALUES” is keyDb.“LMDBJAVA BIG-VALUE” is valueKeyDb
“SMALL-VALUES” is plural because… while “BIG-VALUE” is singular because …
4.2.5 Uses Cases
Example of use of unification in Rholang code from Kent
Contents of Key-Value Store
key | value
anything | rholang-0 // Channel points to ptrn
rholang-0@ | [ rholang-1, rholang-2, rholang-3 ] // ptrn points to the unification_ptr
[ rholang-1, rholang-2, rholang-3 ] | P1, P2, P3 // unification_ptrn points to the actual continuation
GRIFF:
* What does '@' mean at the end of the key "rholang-0@"?
* Will the key array [ rholang-1, rholang-2, rholang-3 ] be represented as a blob?
tree (GRIFF: trie?)
a
n
y
t
h
i
n
g
(rholang-0)
anything!([1, 2, 3 ])
|
for (rholang-0@[ rholang-1, rholang-2, rholang-3 ] <- anything) {
print(rholang-1, rholang-2, rholang-3)
}
|
for (rholang-0@[ rholang-1, rholang-2, rholang-3 ] <- anything) {
print(rholang-1, rholang-2, rholang-3)
}
|
for (rholang-0@[ rholang-1, rholang-2, rholang-3 ] <- anything) {
print(rholang-1, rholang-2, rholang-3)
}
4.3 Unification and Lmdbjava
Working together
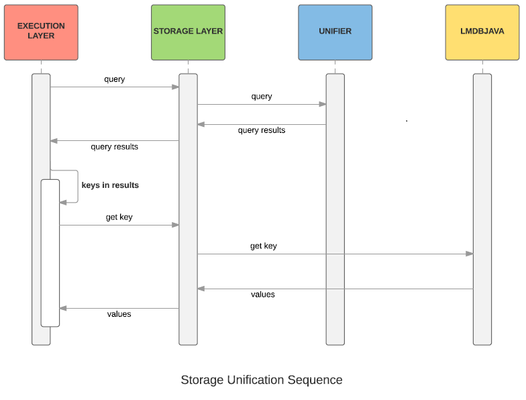 Note that this diagram abstracts out the 2 lmdbjava databases.
Note that this diagram abstracts out the 2 lmdbjava databases.
5 Bibliography
RChain Overview
RChain Platform
Architecturehttp://rchain-architecture.readthedocs.io/en/latest/index.html
"Contracts, Composition, and Scaling: The Rholang 0.1 specification"
RChain Blockchain
Ethereum
enodehttps://github.com/ethereum/wiki/wiki/enode-url-format
Lmdb
Lmdbjava
https://github.com/lmdbjava/lmdbjava
http://www.javadoc.io/doc/org.lmdbjava/lmdbjava/0.6.0
Prolog