This document describes how to we plan to upgrade from the Rchain State Proposal to a sharded version. The word name group and shard are used interchangeably.
Shard Hierarchy
The shard hierarchy forms a tree. Shards at the leaves are identified with a single string and shards at the nodes are identified with sets of strings (representing the union of the children leaf shard identifiers). The root of the tree represents the "root shard", the shard that is identified by the union of all leaf shards. To support sharding, we add an additional shard annotation to Rholang. The syntax will be name: (Type/Sort, [Shard ID 1, Shard ID 2, ..., Shard ID N]), and only channel types can have shard annotations. When you annotate a name N with a shard identifier N_S, any name P with shard identifier P_S that is waiting for the name N as part of its input arguments or mentions N in its body/continuation must have an identifier that contains all elements of the shard identifier N_S, i.e., n ⊆ P_S for all n in N_S. Names that are not annotated with a shard identifier are assumed to have the same shard identifier as the name of the enclosing "for","!", or "contract". If the "for" is a join, then the shard identifier is automatically the union of the names that constitute the join. The name of a top-level "for","!", or "contract" automatically has the shard identifier at the level it was deployed. To prevent too many shards from being generated, a new shard ID can only be generated by declaring a new shard name when deploying, i.e., Deploy(<code>, shard: "0xuniqueshardID").
Examples
The following is a deployment that generates a new shard S1 and stores contract@"Bar" as its first waiting continuation.
Deploy(
contract @"Bar"(...) {
new Foo {
...
}
},
shard: "0xS1"
)
The following valid deployment will be parred into the top level of shard S1.
Deploy(
contract @"Bar"(...) {
new Foo {
contract Foo(baz: (Ch[Int], ["0xS1"])) {...} |
Foo!(...)
}
},
shard: "0xS1"
)
The following deployment is invalid as @"Bar" needs to be deployed to a shard with an identifier that contains at least ["0xS1","0xS2"].
Deploy(
contract @"Bar"(...) {
new Foo {
contract Foo(baz: (Ch[Int], ["0xS1","0xS2"])) {...} |
Foo!(...)
}
},
shard: "0xS1"
)
I've drawn a potential valid Rchain blockDAG simulation below.
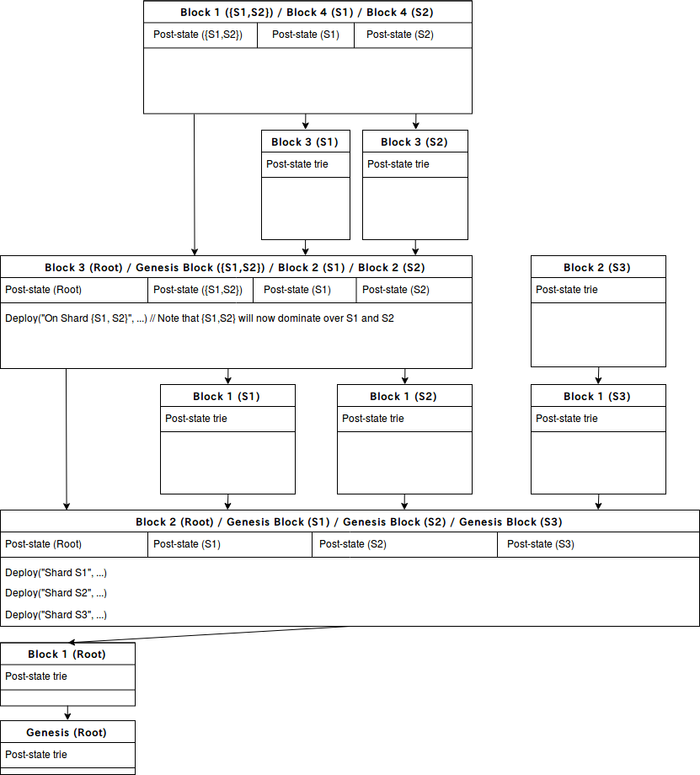 nomenclature still needs some work. For now, I've drawn a potential valid Rchain blockDAG simulation below.
nomenclature still needs some work. For now, I've drawn a potential valid Rchain blockDAG simulation below.
The diagram provides an example of how child shards S1, S2, and S3 are forked off the root shard. It then gives an example of how a sub-hierarchy change is made: someone deploys a contract that has names that span S1 and S2. If one shard dominates over another, then the former can force the latter to accept a merge block and thus change its fork choice. Thus by the end of the diagram the root shard dominates over \{S1, S2\} and S3. And \{S1, S2\} dominates over S1 and S2.
Validator to Shard Hierarchy Mappings
...
Sharding introduces "merge blocks", blocks that are validated across shards in the sharding hierarchy. Merge blocks can only occur along the branch lines of the sharding hierarchy. For example, from the above diagram, we can have a merge block between "S1" and "{S1,S2}"; "S2" and "{S1,S2}"; and "S1", "S2", and "{S1,S2}". But not "S1" and "S2". A "merge block" spans multiple shards and is part of the blockchain of all the constituent shards. Instead of a single state root, each merge block will have multiple state roots (and most importantly multiple Casper contract instances) - one for each shard it merges. Each Casper contract defines the master shard (set) of its children blocks. The master shard (set) chain must not contain cycles.